今天,阿里巴巴通義千問團(tuán)隊(duì)扔出了一枚"重磅炸彈"——正式推出僅320億參數(shù)的QwQ-32B大語言模型。這個(gè)看似中等體量的模型,竟在多項(xiàng)關(guān)鍵指標(biāo)上追平甚至超越了頂尖模型DeepSeek-R1。

從官方披露的數(shù)據(jù)來看,QwQ-32B的突破主要源于強(qiáng)化學(xué)習(xí)技術(shù)的創(chuàng)新應(yīng)用。研發(fā)團(tuán)隊(duì)摒棄了傳統(tǒng)獎(jiǎng)勵(lì)模型,轉(zhuǎn)而通過分階段訓(xùn)練策略:先用數(shù)學(xué)題答案驗(yàn)證和代碼測(cè)試執(zhí)行結(jié)果作為反饋,夯實(shí)基礎(chǔ)推理能力;再引入通用獎(jiǎng)勵(lì)模型擴(kuò)展綜合實(shí)力。這種"精準(zhǔn)投喂"的調(diào)教方式,讓模型在參數(shù)量?jī)H為對(duì)手1/21的情況下,不僅保住了性能基準(zhǔn)線,還把推理成本壓縮到十分之一。有網(wǎng)友實(shí)測(cè)發(fā)現(xiàn),該模型在筆記本電腦上就能流暢運(yùn)行,思考過程還能實(shí)時(shí)可視化,這性價(jià)比直接拉滿。
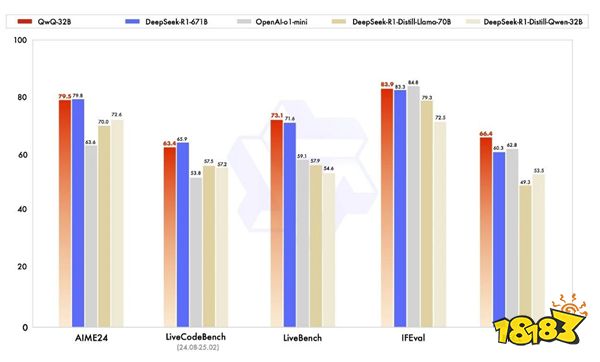
在權(quán)威評(píng)測(cè)中,QwQ-32B展現(xiàn)出了"以小搏大"的硬實(shí)力。面對(duì)被稱為"LLM終極考場(chǎng)"的LiveBench榜單,它不僅以72.5分反超DeepSeek-R1的70分,更以0.25美元的成本遠(yuǎn)低于對(duì)手2.5美元的推理開銷。在代碼生成、數(shù)學(xué)解題等專項(xiàng)測(cè)試中,其表現(xiàn)甚至優(yōu)于部分專門優(yōu)化的蒸餾模型。最令人驚喜的是,它還能像人類一樣在使用工具時(shí)進(jìn)行"自我糾錯(cuò)",根據(jù)環(huán)境反饋動(dòng)態(tài)調(diào)整推理路徑。
這波操作背后的技術(shù)路徑確實(shí)讓人眼前一亮。當(dāng)行業(yè)還在為"萬億參數(shù)俱樂部"的門檻爭(zhēng)得頭破血流時(shí),阿里選擇用強(qiáng)化學(xué)習(xí)深挖模型潛力,某種程度上打破了"參數(shù)即正義"的固有認(rèn)知。正如業(yè)內(nèi)人士評(píng)價(jià),這種中等規(guī)模模型的高效表現(xiàn),既為開源社區(qū)提供了新思路,也降低了企業(yè)部署AI的門檻。
目前該模型已在Hugging Face和ModelScope雙平臺(tái)開源,普通用戶通過Qwen Chat就能直接體驗(yàn)。